[toc]
Conclusion
模型概述
- MPI-FER 模型:
- 通过跨模态翻译和多模态特征融合,将音频和文本数据作为特权信息嵌入到面部表情识别任务中。
- 模型包含三个主要模块:
- 图像-音频模态翻译模块 (IA-MTM):实现图像到音频的跨模态翻译。
- 图像-文本模态翻译模块 (IT-MTM):实现图像到文本的跨模态翻译。
- 多模态特权信息嵌入模块 (MPI-EM):融合图像、音频和文本的情感特征,进行最终的表情分类预测。
主要贡献
- 新颖的多模态特权信息嵌入方法:
- 提出了一种新的方法,通过跨模态翻译将音频和文本数据作为特权信息嵌入到面部表情识别任务中,显著提高了识别准确率。
- 跨模态翻译模块:
- 设计了 IA-MTM 和 IT-MTM,分别实现图像到音频和图像到文本的跨模态翻译,将音频和文本情感信息迁移到图像特征提取过程中。
- 多阶段训练策略:
- 提出了一种模块级预训练后接端到端微调的训练策略,解决了大规模异构网络在有限训练样本下的训练难题。
- 广泛的实验验证:
- 在两个多模态情感数据库(CH-SIMS 和 CMU-MOSI)和两个面部表情数据库(RAF-DB 和 AffectNet)上进行了实验,验证了方法的有效性。
实验结果
- 多模态情感识别:
- 在 CH-SIMS 数据库上,三分类情感识别准确率达到了 83.15%,比第二高的方法提高了 10.28%。
- 在 CMU-MOSI 数据库上,MPI-FER 方法在测试阶段仅使用视觉数据的情况下,仍然比大多数相关方法取得了更高的识别准确率。
- 面部表情识别:
- 在 RAF-DB 数据库上,七分类面部表情识别准确率达到了 87.57%,比基线方法提高了 3.8%。
- 在 AffectNet 数据库上,七分类面部表情识别准确率比基线方法提高了 7.26%,并与 11 种最先进的 FER 方法相当。
未来工作
- 结合 Transformer 模型:
- 未来的工作可以尝试使用基于 Transformer 的模型作为视觉特征提取的骨干网络,结合多模态特权信息嵌入机制,进一步提高表情识别的性能。
Introduction
研究背景
- 传统方法主要通过设计更强大的特征提取模型、引入注意力机制或使用生成模型(如 GAN)来提升 FER 性能。这些方法通常只利用单一模态的数据(如图像),忽略了人类情感的多模态特性。
研究动机
- 多模态数据丰富
- 特权信息是指在训练阶段可以使用但在测试阶段不可用的额外信息。通过将多模态情感数据作为特权信息,可以在训练阶段利用这些数据提升单一模态情感识别的性能。
研究目标
- 提出一种新颖的多模态特权信息嵌入方法:
- 通过将音频和文本数据作为特权信息嵌入到面部表情识别任务中,提升基于图像的情感识别性能。
- 设计一种端到端可训练的异构深度神经网络模型(MPI-FER),实现多模态情感数据的跨模态翻译和特征融合。
- 解决实际应用中的挑战:
- 在训练阶段利用多模态数据,在测试阶段仅使用图像数据完成表情识别。
- 提出一种多阶段训练策略,解决大规模异构网络在有限训练样本下的训练难题。
研究贡献
- 提出了一种新颖的多模态特权信息嵌入方法:
- 通过跨模态翻译将音频和文本数据作为特权信息嵌入到面部表情识别任务中,显著提高了识别准确率。
- 设计了跨模态翻译模块:
- 提出了图像-音频模态翻译模块(IA-MTM)和图像-文本模态翻译模块(IT-MTM),实现音频和文本数据到图像特征的迁移。
- 提出了一种多阶段训练策略:
- 通过模块级预训练后接端到端微调,解决了大规模异构网络在有限样本下的训练难题。
- 广泛的实验验证:
- 在两个多模态情感数据库(CH-SIMS 和 CMU-MOSI)和两个面部表情数据库(RAF-DB 和 AffectNet)上进行了实验,验证了方法的有效性。
Related Work
特权信息学习 (Privileged Information Learning)
- Pan 等人利用非遮挡面部图像作为遮挡面部图像的特权信息,解决了 FER 中的遮挡问题。
- Wang 等人和 Bonnard 等人分别使用面部动作单元(AU)和面部 landmarks 作为特权信息,通过深度神经网络(DNN)提取面部图像的表情特征,并利用特权信息损失(PI loss)将特权信息中的表情特征迁移到面部图像的特征提取中。
多模态情感分析中的特权信息学习
- 跨模态知识迁移:
- Rajan 等人提出了 CM-StEW 模型,通过在训练阶段从更强的模态向较弱的模态迁移知识,以提升单一模态情感识别的性能。该模型使用基于 Transformer 的 DNN 分别从视觉和音频数据中提取特征,并通过深度规范相关性分析(Deep Canonical Correlation Analysis, DCCA)对齐两种模态的潜在特征。
- Han 等人提出了一种跨模态情感嵌入框架,通过训练共享嵌入空间来建模视频和音频数据之间的潜在相关性,并使用 triplet loss 进一步强制跨模态的高级特征共享相似空间。
本文方法
- 跨模态翻译模块的显式结构:
- 与上述相关方法不同,本文提出的 MPI-FER 模型中的跨模态翻译模块(IA-MTM 和 IT-MTM)不仅创建了中间联合特征空间,还显式地学习了两种模态表示之间的转换。
- 这种结构使得在测试阶段仍然可以显式地进行多模态特征提取,而其他相关方法通常仅在训练阶段使用多模态辅助数据,通过“幻觉”网络进行知识迁移,这些网络在测试阶段不可用。
- 更复杂的融合机制:
- 本文方法在测试阶段可以使用更复杂的融合机制,而上述相关方法通常仅使用单一模态识别网络。
- 新的实验协议:
- 本文提出了一种新的实验协议,利用多模态情感数据库的数据作为特权信息,以提升常用面部表情数据库的识别准确率。这使得本文方法在 FER 研究中具有实际应用价值,而相关模型通常在同一数据库内实现。
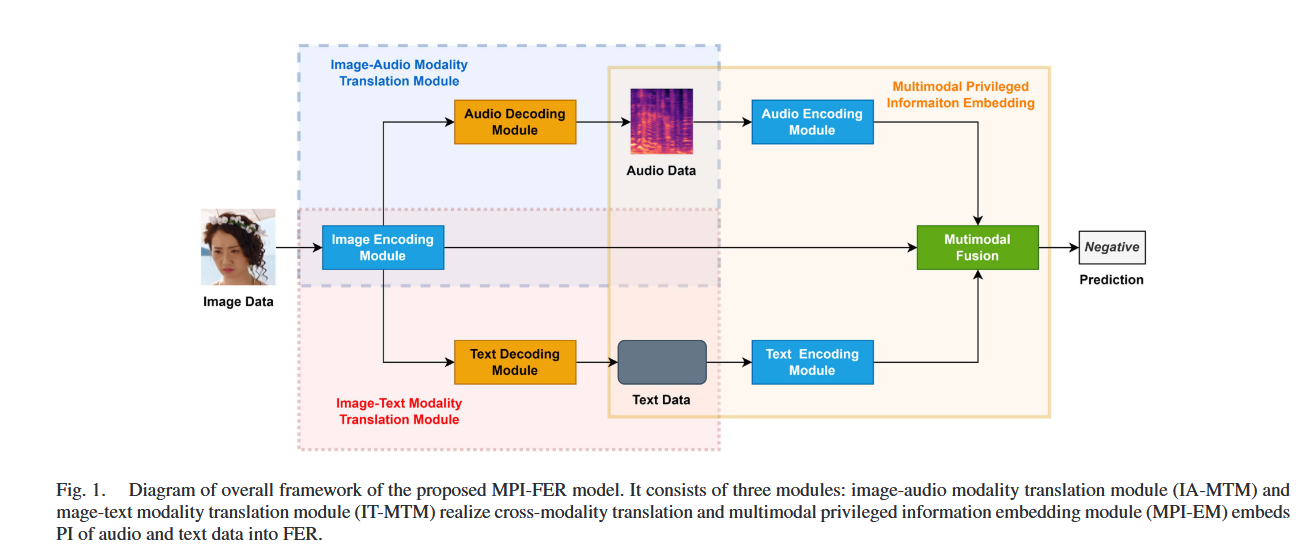
Multimodal Privileged Information Embedded Facial Expression Recognition Network (MPI-FER)
一种端到端可训练的异构深度神经网络模型,旨在通过将多模态情感数据(如音频和文本)作为特权信息嵌入到面部表情识别 (FER) 任务中,提升基于图像的情感识别性能。
总体架构
- 图像-音频模态翻译模块 (Image-Audio Modality Translation Module, IA-MTM):
- 实现图像到音频的跨模态翻译。
- 将音频情感信息迁移到图像特征提取过程中。
- 图像-文本模态翻译模块 (Image-Text Modality Translation Module, IT-MTM):
- 实现图像到文本的跨模态翻译。
- 将文本情感信息迁移到图像特征提取过程中。
- 多模态特权信息嵌入模块 (Multimodal Privileged Information Embedding Module, MPI-EM):
- 融合图像、音频和文本的情感特征,进行最终的表情分类预测。
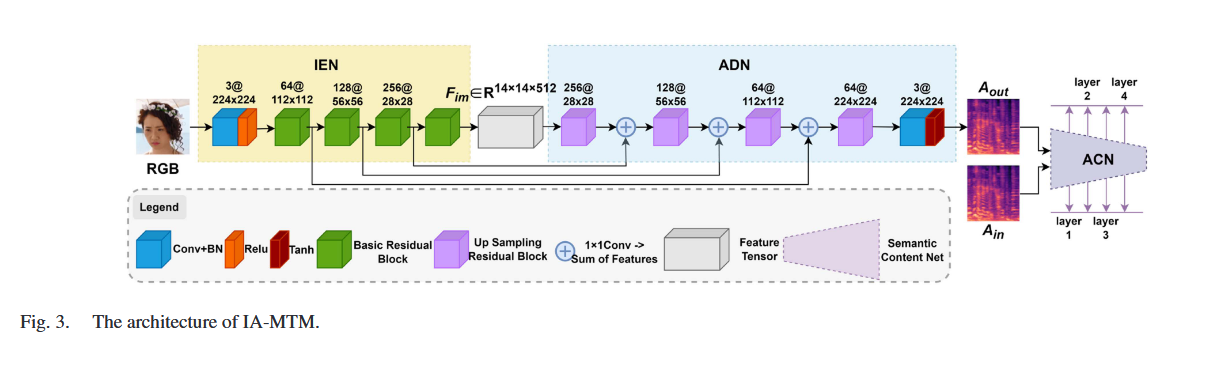
图像-音频模态翻译模块 (IA-MTM)
结构:
- 图像编码网络 (Image Encoding Network, IEN):
- 采用 ResNet18 作为骨干网络,用于提取图像特征。
- 输入图像经过 IEN 编码生成图像特征(Image Emotion Feature, IEF)。
- 音频解码网络 (Audio Decoding Network, ADN):
- 将 IEN 提取的图像特征解码为音频数据(Mel 谱图)。
- 包含四个残差上采样层和一个卷积层,用于重建 Mel 谱图。
- 通过卷积跳跃连接将不同尺度的特征融合到合成的 Mel 谱图中。
- 音频决策网络 (Audio Classification Network, ACN):
- 用于缩小合成音频和真实音频之间的差异。
- 包括外观损失(MSE)和特征损失(使用预训练的 Mel 谱图音频情感识别 CNN 模型提取特征)。
工作流程:
- 输入图像经过 IEN 编码生成 IEF。
- IEF 输入到 ADN,解码生成合成的 Mel 谱图(Aout)。
- ACN 对 Aout 和真实 Mel 谱图(Ain)进行判别,计算损失并优化模型。
作用:
- 通过跨模态翻译,将音频情感信息迁移到图像特征提取过程中。
- 提高模型对图像中表情特征的提取能力。
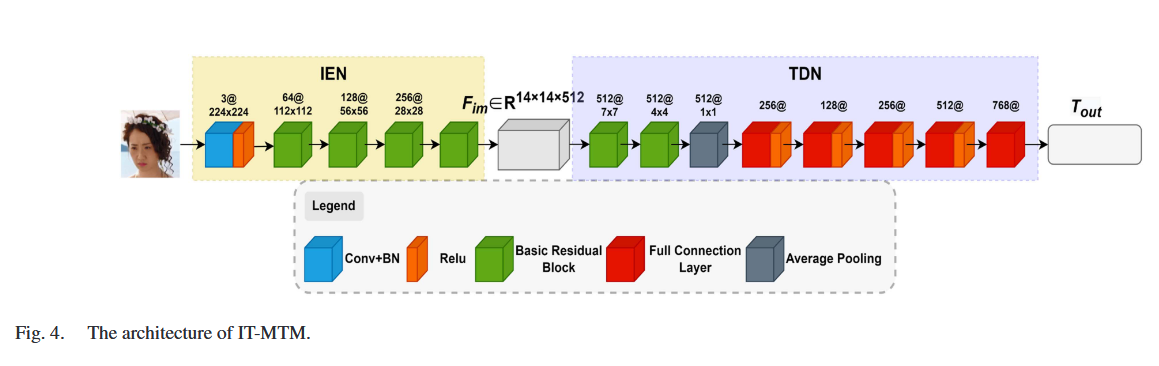
图像-文本模态翻译模块 (Image-Text Modality Translation Module, IT-MTM)
结构:
- 图像编码网络 (Image Encoding Network, IEN):
- 重用 IA-MTM 中的 IEN,用于提取图像特征(IEF)。
- 文本解码网络 (Text Decoding Network, TDN):
- 将 IEF 解码为文本表示(Tout)。
- 使用 CNN 结构,输出与 BERT 模型基于类的特征维度(768 维)一致的向量。
工作流程:
- 输入图像经过 IEN 编码生成 IEF。
- IEF 输入到 TDN,解码生成合成的文本表示(Tout)。
- 使用 MSE 损失函数计算 Tout 和真实文本表示(Tin)之间的差异,并优化模型。
作用:
- 通过跨模态翻译,将文本情感信息迁移到图像特征提取过程中。
- 提高模型对图像中表情特征的提取能力。
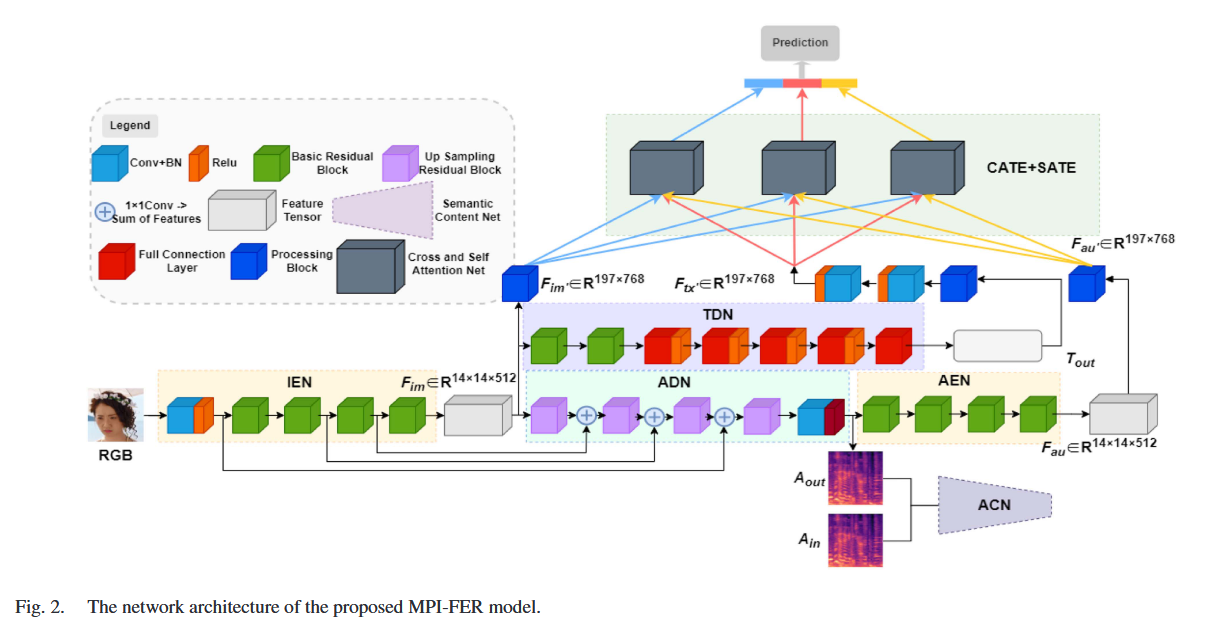
多模态特权信息嵌入模块 (Multimodal Privileged Information Embedding Module, MPI-EM)
结构:
- 音频编码网络 (Audio Encoding Network, AEN):
- 对 IA-MTM 生成的合成音频数据(Aout)进行特征提取,生成音频特征(Fau)。
- 使用与 IEN 相同的 CNN 模型。
- 文本编码网络 (Text Encoding Network, TEN):
- 对 IT-MTM 生成的合成文本数据(Tout)进行特征提取,生成文本特征(Ftx)。
- 由于 Tout 是向量,首先将其复制成矩阵,然后输入到多个卷积层中进行特征提取。
- 多模态融合网络 (Multimodal Fusion Network, MFN):
- 基于 Transformer 的交叉注意力机制(Cross-Attention Mechanism),融合图像、音频和文本的情感特征。
- 包含三个交叉注意力融合块(Cross-Attention Fusion Blocks, CAFB),每个 CAFB 包括两个交叉注意力 Transformer 编码器(CATE)和两个自注意力 Transformer 编码器(SATE)。
- 最终将融合后的特征连接到 softmax 层,输出表情分类结果。
工作流程:
- AEN 对 Aout 进行编码,生成 Fau。
- TEN 对 Tout 进行编码,生成 Ftx。
- IEN 提取的 IEF、AEN 提取的 Fau 和 TEN 提取的 Ftx 输入到 MFN。
- MFN 使用交叉注意力机制融合三种模态的特征,生成最终的表情分类结果。
作用:
- 将多模态情感数据作为特权信息嵌入到 FER 任务中。
- 通过交叉注意力机制,高效地学习三种模态特征之间的互补信息,提高表情分类的准确性。
MTM 和 IT-MTM 分别将音频和文本情感信息迁移到图像特征提取过程中,而 MPI-EM 则通过交叉注意力机制融合三种模态的特征。
EXPERIMENTS AND DISCUSSION
数据集和实验设置
数据集
- CH-SIMS 数据库:
- 中文多模态情感分析数据库,包含 2,281 个视频片段,标注为负面、中性或正面情感。
- 数据库分为训练集(1,368 张图像)、验证集(456 张图像)和测试集(457 张图像)。
- 视觉数据使用视频中间帧表示,音频数据使用 Mel 谱图表示,文本数据使用 BERT 特征表示。
- CMU-MOSI 数据库:
- 英文多模态情感分析数据库,包含 93 个视频,分割为 2,198 个语音片段,标注为情感强度(-3 到 3)。
- 数据库分为训练集(1,283 个片段)、验证集(229 个片段)和测试集(686 个片段)。
- RAF-DB 数据库:
- 面部表情数据库,包含 29,672 张图像,标注为七种基本表情。
- 数据库分为训练集(12,271 张图像)和测试集(3,068 张图像)。
- AffectNet 数据库:
- 大规模面部表情数据库,包含约 450,000 张面部图像,标注为七种基本表情。
- 数据库分为训练集(280,000 张图像)和测试集(3,500 张图像)。
实验设置
- 优化器:Adam,初始学习率 0.0002,每 50 个 epoch 衰减 10 倍。
- 批量大小:32。
- 迭代次数:150 个 epoch。
- 框架:PyTorch。
- 硬件:Intel Xeon 2.40 GHz 8 核 CPU,128 GB 内存,NVIDIA GV100 GPU。
消融实验
特权信息嵌入的有效性
- 基线方法:使用 ResNet18 作为视觉特征提取器。
- 实验结果:
- 在 CH-SIMS 数据库上,使用音频和文本作为特权信息的 MPI-FER 方法在三分类情感识别任务中达到了 83.15% 的准确率,比基线方法提高了 1.93%。
- 在 RAF-DB 数据库上,MPI-FER 方法在七分类面部表情识别任务中达到了 86.57% 的准确率,比基线方法提高了 2.8%。
不同融合机制的比较
- 比较方法:加法、拼接和点积三种基线融合机制。
- 实验结果:
- 在 CH-SIMS 和 RAF-DB 数据库上,交叉注意力融合机制的准确率最高,分别达到了 83.15% 和 86.57%。
- 拼接融合机制的性能最差,因为其特征维度较大,增加了后续 softmax 层的识别难度。
多阶段训练策略的有效性
- 实验结果:
- 使用多阶段训练策略的 MPI-FER 模型在 CH-SIMS 和 RAF-DB 数据库上分别比从头训练的模型提高了 1.31% 和 1.86%。
- 模块级预训练为模型提供了良好的初始化权重,降低了大规模异构网络的训练难度。
跨模态翻译的性能
- t-SNE 可视化:
- 合成的 Mel 谱图和文本表示与真实数据的分布高度一致,证明了 IA-MTM 和 IT-MTM 的有效性。
- 合成数据展示:
- 合成的 Mel 谱图与真实 Mel 谱图在情感类别上表现出明显的差异,进一步验证了跨模态翻译的有效性。
基于多模态情感数据库的实验
CH-SIMS 数据库
- 实验结果:
- 在二分类、三分类和五分类情感识别任务中,MPI-FER 方法分别比第二高的方法提高了 10.48%、10.28% 和 2.19%。
- 使用中间帧作为视觉表示比数据库提供的原始视觉特征更有效。
CMU-MOSI 数据库
- 实验结果:
- 在英语多模态情感识别任务中,MPI-FER 方法在测试阶段仅使用视觉数据的情况下,仍然比大多数相关方法取得了更高的识别准确率。
基于面部表情数据库的实验
RAF-DB 数据库
- 实验结果:
- MPI-FER 方法在七分类面部表情识别任务中达到了 87.57% 的准确率,比基线方法提高了 3.8%。
- 与 13 种最先进的 FER 方法相比,MPI-FER 的性能优于大多数基于 CNN 的方法,并与基于 Transformer 的方法相当。
AffectNet 数据库
- 实验结果:
- MPI-FER 方法在七分类面部表情识别任务中比基线方法提高了 7.26%,并与 11 种最先进的 FER 方法相当。
If you like this blog or find it useful for you, you are welcome to comment on it. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you !